ai
“AI-pilled”
AI-pilled: n. A rite of passage where an individual becomes fully awakened to AI’s possibilities, often triggered by an intense hands-on session—sometimes leading to a sleepless night of experimentation and awe.
AI-pilled: n. A rite of passage where an individual becomes fully awakened to AI’s possibilities, often triggered by an intense hands-on session—sometimes leading to a sleepless night of experimentation and awe. Once AI-pilled, people tend to see machine intelligence as a force reshaping nearly every domain. Skepticism and detachment give way to enthusiastic engagement, even evangelism.
(from The Dictionary of Present Futures)
In January last year, we wrote about how “AI seemed to be everywhere,” and that the technology was certain to start impacting the capital markets soon. Turns out, 16 months is an eternity in this space, and the numbers I quoted then now look positively quaint. Anthropic raised funding at a $60billion valuation in early 2025. Today, it’s looking at raising at a $900billion valuation, and investors are supposedly chasing shares in the secondary market at valuations of over $1trillion.
Financial records aside, there has also been a definitive “vibe-shift” in the past 12 months. About a year ago, there were concerns that AI progress might be slowing down. But something happened in the second half of 2025 that has led to a new wave of both excitement and paranoia.
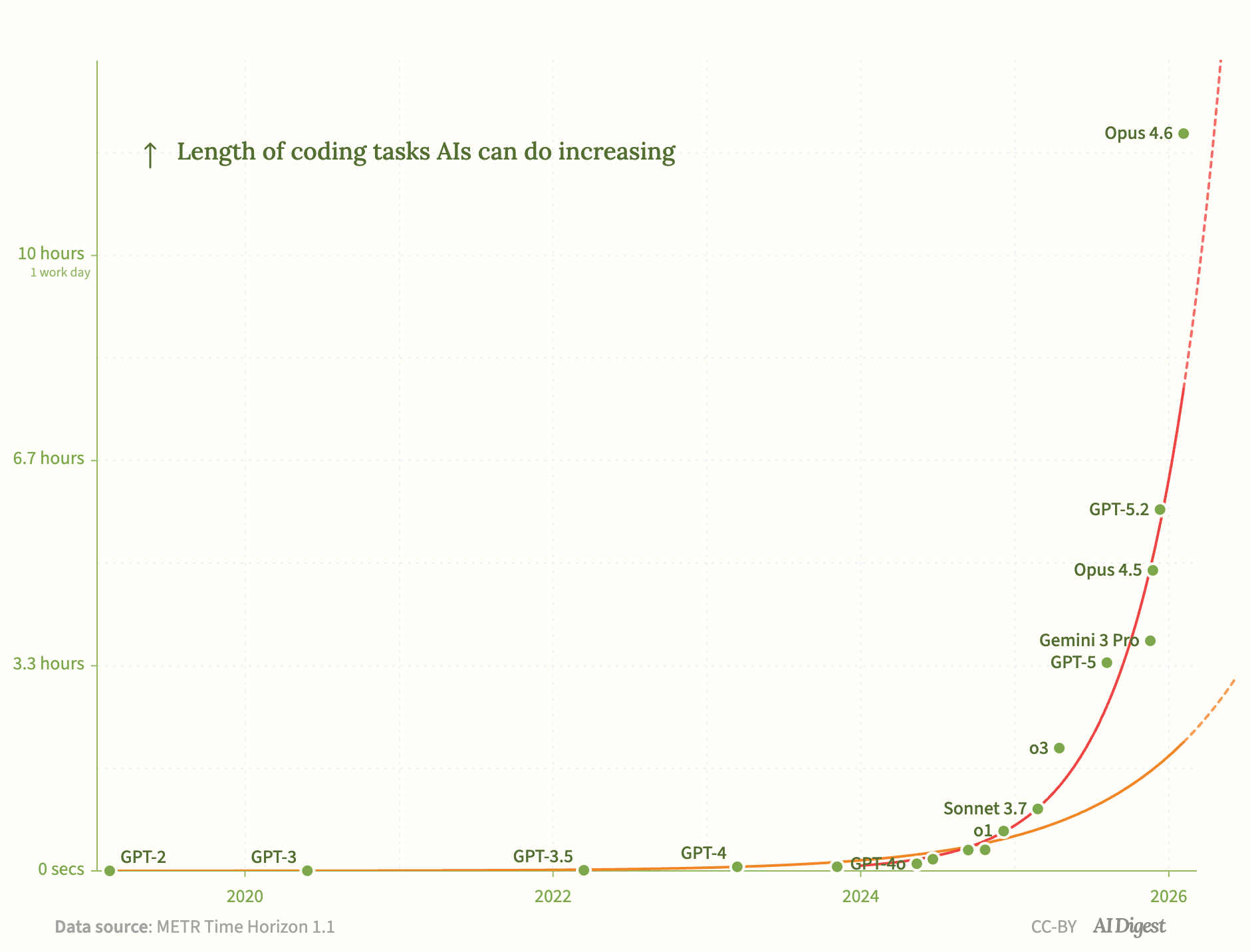
The best way to explain it is by looking at the new “Moore’s law” for AI: the length of time an AI model can work autonomously and still produce accurate results. The organisation METR has been testing each new model release against this metric, giving us a helpful view onto the rate of progress. Their findings? This time frame has been doubling roughly every 7 months. As with any exponential growth curve, humans can be oblivious to its progress for quite a while until it suddenly hits us as if it came out of nowhere.
When ChatGPT came out in November 2022, the window was about 3 minutes. Two years later, in 2024 when Sonnet 3.5 came out, that window had grown to about 21 minutes.
Last year, we started busting through some big thresholds.
- In Feb ‘25, Sonnet 3.7 hit 1 hour
- In April ‘25, o3 hit 2 hours
- In November ‘25 Google’s Gemini 3Pro hit nearly 4 hours
A model that can work for an hour or two suddenly becomes capable of understanding a complex code library, or can produce deep research on a topic from scratch. By mid 2025, you could ask most major AI models to produce a 40-50 page report on nearly any topic, and it could, in “one-shot,” produce a graduate level result for you. This in itself is an amazing achievement, and many people are only just now discovering this capability.
The latest generation of models (Opus 4.6, etc) has just blown all that out of the water.
- In Feb ‘26, Opus 4.6 hit nearly 12 hours
- Some reports suggest that last week’s GPT 5.5 can work for even longer
These models can run an entire project autonomously from start to finish - starting out by creating a project plan / to-do list, spawning multiple sub-agents and delegating tasks to those agents, writing code, running tests, failing, reading logs, debugging, and trying again until successful - all without any human intervention.
The party tricks of 2022-2023 (“write me a poem about interest rates in the form of a Shakespearean sonnet”) have given way to real, substantial changes in the way we work.
But these changes haven’t diffused throughout society yet at the same pace, leading to a huge discrepancy in how people perceive AI, its capabilities, and ramifications for the future.
Straddling both worlds
At Origin, we have an unusual vantage point.
As a technology business, we are fully up to speed on each latest model release. We use AI to help us build our product, and we use AI within our product, and are doing increasingly more of both.
Internally, we’re unrecognizable from the company we were in 2022 when ChatGPT was launched. Our software engineers are multiple times more productive than they were. AI is embedded across our workflows on tasks like presentation design, data analysis, document review, and proposal writing - and increasingly plays a role as a strategic advisor on product and business questions.
The past 12 months have been the most exciting period for our company since we launched 11 years ago.
It’s fair to say that we at Origin are “AI-pilled.”
But unlike many of those in the SF/tech bubble, we also have one foot in the “real world” with our client base of large, conservative, regulated, financial institutions.
A few months ago, an essay written by an AI founder warning of a coming economic apocalypse went viral, picking up 86 million views on X. His thesis rests on the idea that AI will be successfully applied to all work evenly and equally successfully.
He couldn’t be more wrong. And the reason has nothing to do with enterprise IT caution or data security (though those are also impediments). It has to do with how modern AI actually learns, and the fundamental difference between different types of tasks.
Deterministic vs non-deterministic work
Everyone knows that LLMs are “pre-trained” on larger and larger datasets of text, code, etc. The larger the pre-training data set, the more it has “seen” before, so the deeper its knowledge base.
But, increasingly, the most significant improvements come after pre-training, with something called “Reinforcement Learning” (RL). In RL, the model is given a series of tests (evals), and rewards for passing them. The model’s goal is to maximize its rewards.
(RL, combined with “thinking” - basically asking the model to pause and “talk to itself” - is what heralded the most recent breakthroughs in model performance, starting with OpenAI’s o1 in late 2024).
How does RL work across different domains?
Math? Easy. There’s only one answer to any given question, and it’s 100% objective. When the model gets the answer right, it gets the reward.
Software engineering? Similarly easy. There might be multiple ways to solve a coding problem, but, the question of whether the problem has been solved, is easy to check. You can just run the code. If I want a program to do X, Y, and Z, and my AI writes a program that only does X and Z, it has to try again.
Crucially for the above two tasks, the RL feedback loop (run -> test -> reward -> iterate -> run again) can be run automatically on a machine. The velocity of learning is incredibly high.
Now consider writing an email. Imagine the prompt: “Write an email to my boss asking for next Friday off.” There are 100s of ways to complete that task. Which were successful? How do you set up the eval? Which versions should be more highly rewarded?
Or even better - design a 5 slide powerpoint deck on this topic. How would you eval that?
These tasks have two fundamental differences:
- The “answers” are not objectively true.
- The “evaluator” is a human, rather than a machine. So the velocity of learning is much slower.
Tasks fall on a spectrum from deterministic to non-deterministic.
At one end, there’s coding, math, structured data analysis etc. The answer is objective and you want the model to converge on it every single time. At the other end you have creative writing, design, and strategic judgement.
Much of knowledge work sits somewhere along that spectrum.
Progress can still be made on non-deterministic work. (This is why the leading labs are hiring former bankers and other professionals to do RL in these domains.) But, there still remains a fundamental difference between deterministic work vs non-deterministic work.
This is the gap the “AI-pilled” SF pundits underestimate. The question isn’t just “how good can the AI get” … it’s also a question of “how good do I need it to be?”
Finance + Tech + Law
At Origin, we sit at the intersection of financial, technology, and law, and the tasks in our world span the entire spectrum. This framework helps predict where AI excels and where it struggles.
Data Analysis → Excellent. Try throwing any complex CSV into an AI and ask it to generate a set of charts for you, or summarise conclusions. Hours of work, gone.
Legal document summarisation → Also strong. Need to read through a 30 page contract and quickly find the relevant points of contention. Done in seconds.
Pitch deck design → Useful for a first draft, but needs human polish. Will this resonate with the client? The eval here is subjective … hard to generalise.
Legal document generation → Here’s where it gets interesting.
AI can generate high quality PhD level documents on most topics. And if you ask an AI to draft a legal contract for you, it has enough pre-training data to produce a very good output.
But there’s something fundamentally different between a 10 page research report and a 10 page legally binding contract. If the text in the research report comes out slightly differently each time - a concept is summarised differently, or a different anecdote is used - there’s no fundamental change in success. The reader still learns about the topic.
However, a legal document is the opposite. If the 10 page contract isn’t 100% precise down to the word, the functional meaning of the contract changes. Legal contracts are like code…they need a deterministic outcome. But unlike code, you can’t “run” them to check. You can train against precedent documents, but those were drafted by hand and contain inconsistencies that may or may not matter.
“AI-pilled” in DCM
When we look at the future of the bond market, we see a market where the work will fundamentally change, but where the players, and their relationships with each other will look strikingly similar.
The deterministic sub-tasks such as analysing comparables, drafting termsheets, or doing regulatory checks, these will get easily automated. But a “go, no-go” call during a shaky market, coming up with a new structure, uncovering a novel pool of investor capital, these are the tasks where humans will earn their keep, and stay relevant for far longer than SF predicts.
Bond documentation sits in the interesting middle. The content is legally binding and needs to be precise to the word. But much of it is templated, rule-based, and structured. That makes it exactly the kind of work where humans, deterministic rules, and AI together dramatically outperform any of them alone: the rules handle what should be deterministic, AI accelerates the work around them, and humans stay in the loop where judgment matters.
That's the bet behind Origin. Being "AI-pilled" in DCM doesn't mean believing AI changes everything. It means being prescient enough to spot what will change, experienced enough to know what won’t, and confident enough to lean in.


